J'ai vibecodé un classeur de fichiers par IA locale
Les vacances, c'est régler les sujets qui prennent la poussière. Il y a quelques années, j'ai scanné une bonne centaine de contrats, de fiches de paie et autres documents chiants. Ils vivent depuis en vrac dans un dossier "Scanned Documents". S'y sont ajoutés des dizaines de documents administratifs depuis.
Je n'ai jamais eu le courage de tout traiter à la main.
Les vacances ont donc été l'occasion de créer un petit outil de tri par IA locale. 3 défis :
- A part quelques sites sous Wordpress, j'ai rarement codé. Donc ce sera du vibecode
- Je n'ai jamais rien mis sur GitHub
- Le script doit tourner sur un laptop vieux de sept ans, sous Linux
Simple mais long
Ca donne Renommai, un script écrit en 2 jours, fondé sur ollama et un modèle d'IA minuscule.
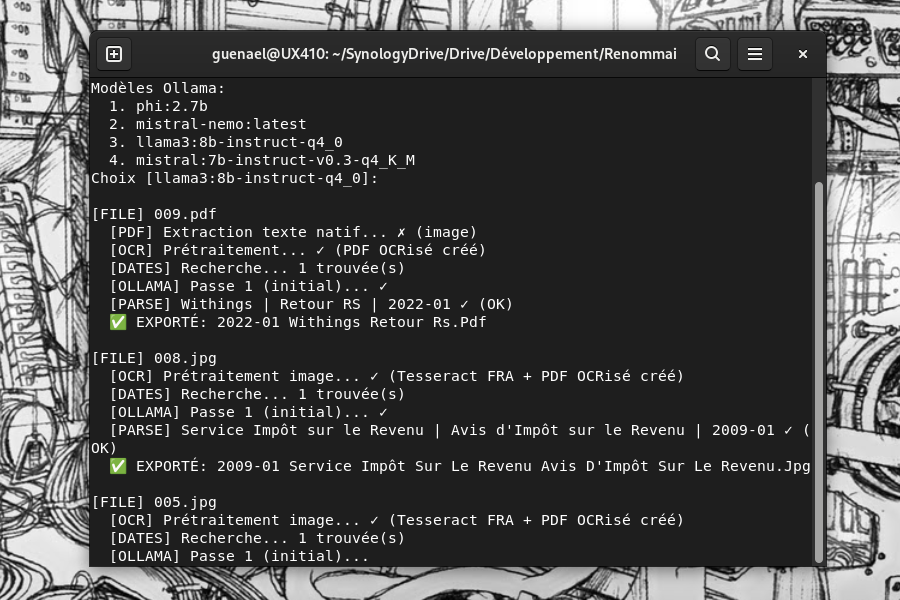
Ce script scanne les images et PDF d'un dossier, fait une passe d'OCR et envoie le fichier ou l'OCR à ollama pour qu'il en tire la date, l'institution émettrice et son objet.
Il place ensuite les fichiers dans des sous-dossiers d'export et d'échec, si l'une des trois entrées (date, institution ou objet) n'est pas identifié.
Le lancement est aussi simple que possible, avec le dossier contenant les fichiers et le choix du modèle ollama à chaque fois. Cette configuration est enregistrée dans un fichier dédié.
Ca donne un script Python de près de 1 000 lignes. Très long pour ce que c'est, je trouve. Mais fondé sur des outils open source.
Salut ça gaze ?
Quasi deux jours pour obtenir une application minimale de tri de fichiers ? J'aurais plus vite fait de les traiter à la main. Mais c'est effectivement amusant.
J'ai d'abord demandé au Chat de Mistral de me créer un script. Fonctionnel, il m'a directement donné de bons résultats, avec des instructions minimales. Seules demandes : OCR le document, en extraire tout le texte via un modèle de vision (via ollama) et renommer via un petit modèle d'IA via ollama. Mais j'ai été rapidement limité par la formule gratuite.
J'ai donc collé dans VS Code et passé à Raptor-mini, le modèle gratuit de Microsoft.
Raptor-mini a abouti à une usine à gaz. Ma demande naïve de "refactor" a donné des fichiers avec près de 2 000 lignes au total je pense. Il est d'ailleurs difficile de retrouver son "fil de pensée" après ses réflexions. Il semble comprendre ce que je veux dire, mais complique vite la solution. Sans trop le dire, Mistral et Raptor ont délégué l'analyse de la date à d'autres outils qu'ollama. J'ai donc tout repris du début :
VS Code m'a généré un texte détaillant toutes les fonctionnalités et la logique de mon script de départ, et de celui créé par les IA dans VS Code, en combinant les deux. J'ai ensuite demandé à Copilot de recréer un script à partir de ces fonctionnalités. Cette documentation est maintenue à jour régulièrement par l'IA depuis.
Après avoir vite atteint le quota gratuit, j'ai pris un premier mois de Copilot Pro (aussi gratuit). Clairement, l'appel de la première dose fonctionne.
Bof pour de la prod
Y allant sans méthode, j'ai fonctionné par essai et erreur. Ollama indiquait d'abord les commentaires dans les noms de fichier, ne lisait pas non plus les tableaux avec un mauvais contraste, ne lisait pas les dates écrites à 90° ou marquées en format "1er janvier 1970". Il a fallu aussi ignorer les dates sortant des 20 dernières années. Et améliorer la détection des institutions et du sujet, en choisissant le meilleur de 3 détectés. Autant de problèmes plus ou moins réglés par des ajouts de fonctionnalités. Et une avalanche de dépendances.
Raptor-mini est obsédé par les tests unitaires, donc il en a exécuté des dizaines, en mangeant toute mon allocation gratuite au passage. Mais il ne pense pas à la sécurité. J'ai retrouvé des dizaines de fichiers temporaires dans le dossier /tmp de mon laptop. J'ai ajouté une routine de suppression à la fin du script ou lors de son interruption.
Le script tournait d'abord sur une copie complète de mon dossier "Scanned Documents". J'ai fini par créer un lot de neuf fichiers de test que je sais plutôt difficiles.
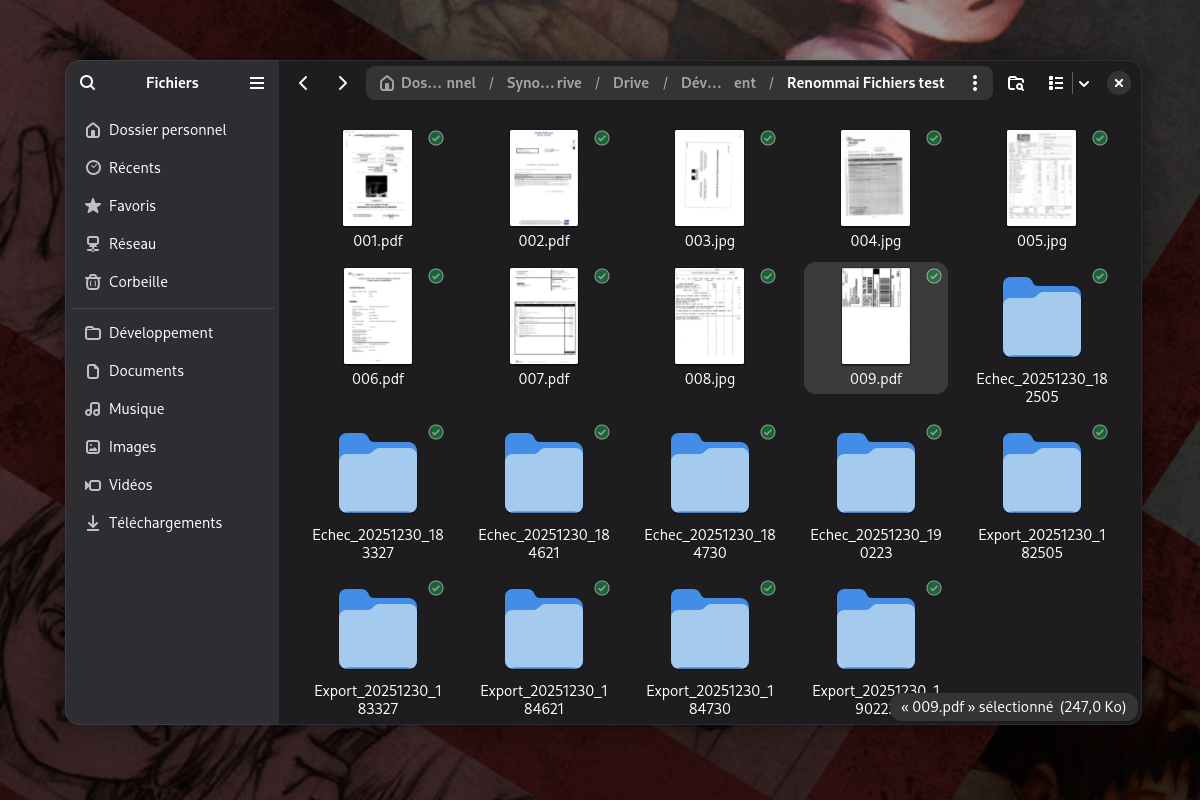
J'ai donc passé mon temps à interrompre mon script et à l'éditer par IA pour aplatir les problèmes rencontrés.
Un poil addictif
Ce système donne bien un sentiment de liberté. Peu d'efforts, des IA qui répondent toujours "oui" aux demandes farfelues et une vitesse qui pousse à itérer.
Je lui ai par exemple demandé de proposer plusieurs noms de fichier plutôt qu'un, et continuer le traitement de la file sans attendre la réponse. Claude a créé de lui-même un parcours clair, et ajouté de lui-même une invite d'édition manuelle du nom.
Claude est excellent pour écrire, déboguer une erreur de traitement (un fichier "inconnu" alors que le texte a bien été lu) et même recommander d'autres modèles. Remplacer le modèle de vision Llava (et même llava-llama3) par Minicpm-v a beaucoup aidé, sur son conseil.
Pour l'envoi sur GitHub, j'ai juste utilisé les outils d'envoi automatisés de VS Code. Quasi aucune compétence requise, tout est plutôt explicite. J'ai appris quelques leçons, comme sortir les fichiers de test du dossier du dépôt, même avec un .gitignore.
Oh mon vieux laptop
Le but est de le faire tourner sur un laptop ASUS avec un Intel Core i7 de 8e génération (2017) et 16 Go de RAM. Il faut donc choisir le bon modèle et calibrer les instructions (prompt) pour sortir un nom de fichier.
J'ai commencé avec Mistral 7b avec des résultats moyens. Llama 3-8b donne de biens meilleurs résultats, même s'il se trompe encore beaucoup. Sûrement l'issue de la taille des modèles et du manque de ressources.
Le modèle d'IA met plusieurs minutes à analyser chaque fichier. Au point de faire planter les tests unitaires de Raptor-mini, qui ne voulait pas autant attendre.
Comme le reste, le prompt est écrit et affiné par les IA. En dernier Claude Haiku, avec pour instruction de le faire tenir dans 4 000 jetons de contexte. Il a donc surdétaillé la requête. Est-ce la meilleure approche ? Dur à dire.
Je dois encore le faire traiter tout mon dossier, sur le laptop et ensuite mon PC de bureau avec de plus gros modèles. Wish me luck.